Newsletter Title: You have 832ms. Make some AI magic.
You have 832ms. Make some AI magic.This was the boundary. The constraint that seemed almost impossible to reach.But we did it.
I have a strong background in real-time data, so synchronizing data values across great distances in less than 250ms is not foreign to me. Doing it with generative AI is a very different beast. The challenge can be summed up like this:
… and in less than 832ms.¹ It was a long journey. The project is extremely secretive and will continue well into 2025. Still, the people who comprise our small AI team and the vendors we worked with can be celebrated for achieving this performance milestone. Their technical support team floors me. They will answer questions on Sunday morning at 7 a.m. on Slack. Who does that? I won’t go off on a rant expressing my admiration of the Deepgram platform. Still, I cannot avoid reflecting on the architecture and flexibility of the Voice API for building real-time agents. We are deeply intimate with this API, and Deepgram was gracious with their time and patience as we became thoroughly familiar with customization options. This project is researched, built, and tested in Replit—100%. It was a slow start. Some of us were contemplating AWS tools and services. We explored Cursor and Hugging Face Spaces. And, of course, VSCode and CoPilot were in the mix. The cool thing is that we never forced anyone on the team to adopt Replit—it happened organically. Replit won on merit, and it did so without Replit Agent. I called it in 2021. I told everyone who would listen to get on Replit to transform development productivity. I wrote about the advantages of Replit a few times and mentioned it frequently like this passage:
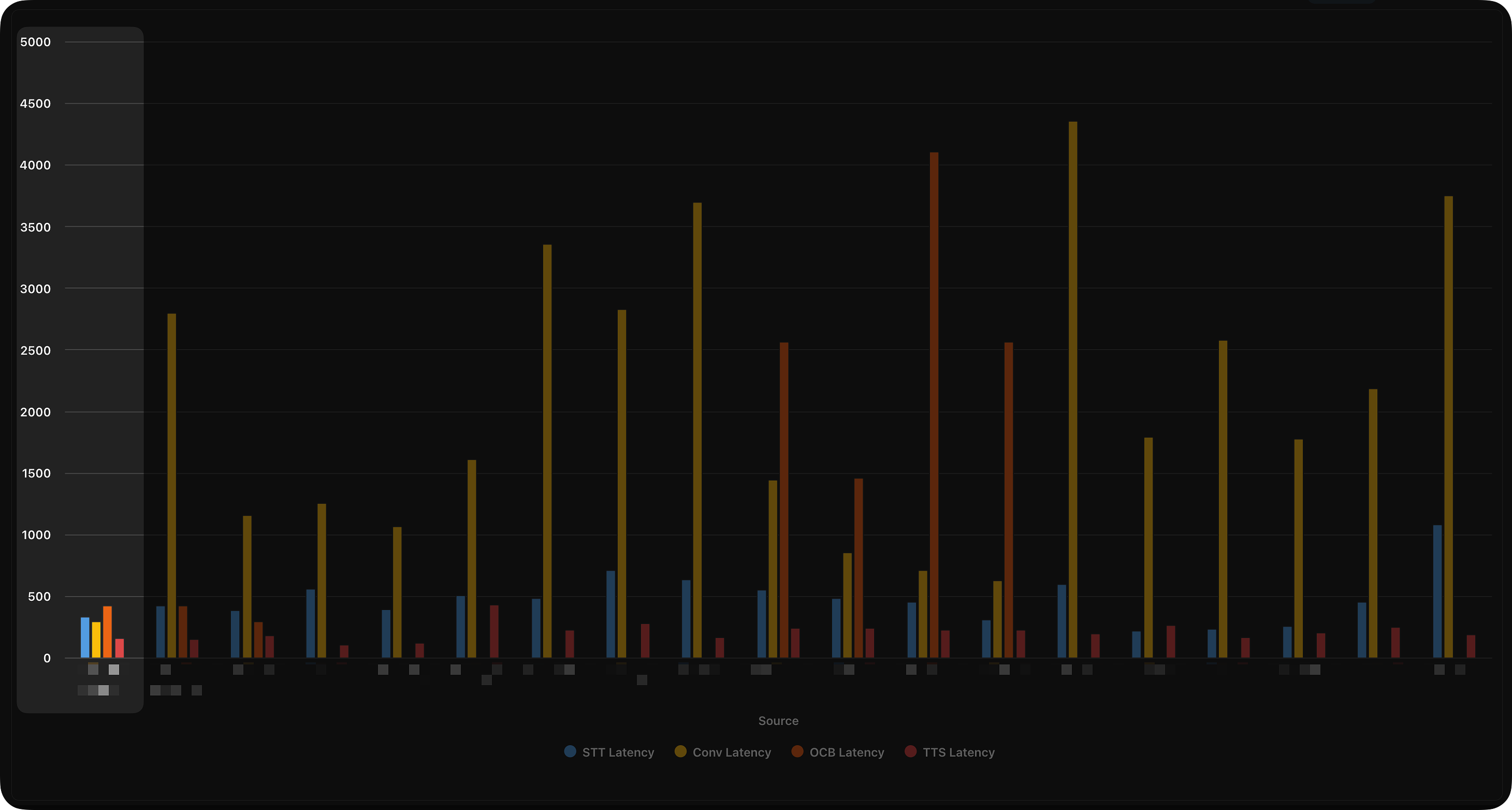
We now use Claude exclusively in our Replit development and documentation work. Our entire project and content management happen exclusively in Coda. But we took it further by building Coda apps that automatically test and rank AI outcomes. Packs, of course, play a significant role. We use Coda as a testing and measuring platform for all AI work. Tracking the latency and AI performance chart shown above is an aggregation of many tests that push analytics into Coda through webhooks. The Team One of the best teams I have ever worked with. John Gibbs (aka Dr. Know It All), Vanessa Fitzgerald, Ben Flanders, Roya Barhaloo, and Lance King—all professionals learning very fast, and adapting to all that is real-time AI. The Tech This project is secretive, with lots of NDAs and several intra-organizational dependencies. What can be divulged with shallow abstractions may be of interest.
This project is not yet finished, but I am already looking to the future, hoping our next client will hire us to make some AI magic in less than ten seconds. 1 Two of the bars in the chart are asynchronous processes. If you thought the combined milliseconds of the bars exceeded 832ms, you’d be misunderstanding the data. You're currently a free subscriber to Impertinent. For the full experience, upgrade your subscription.
|