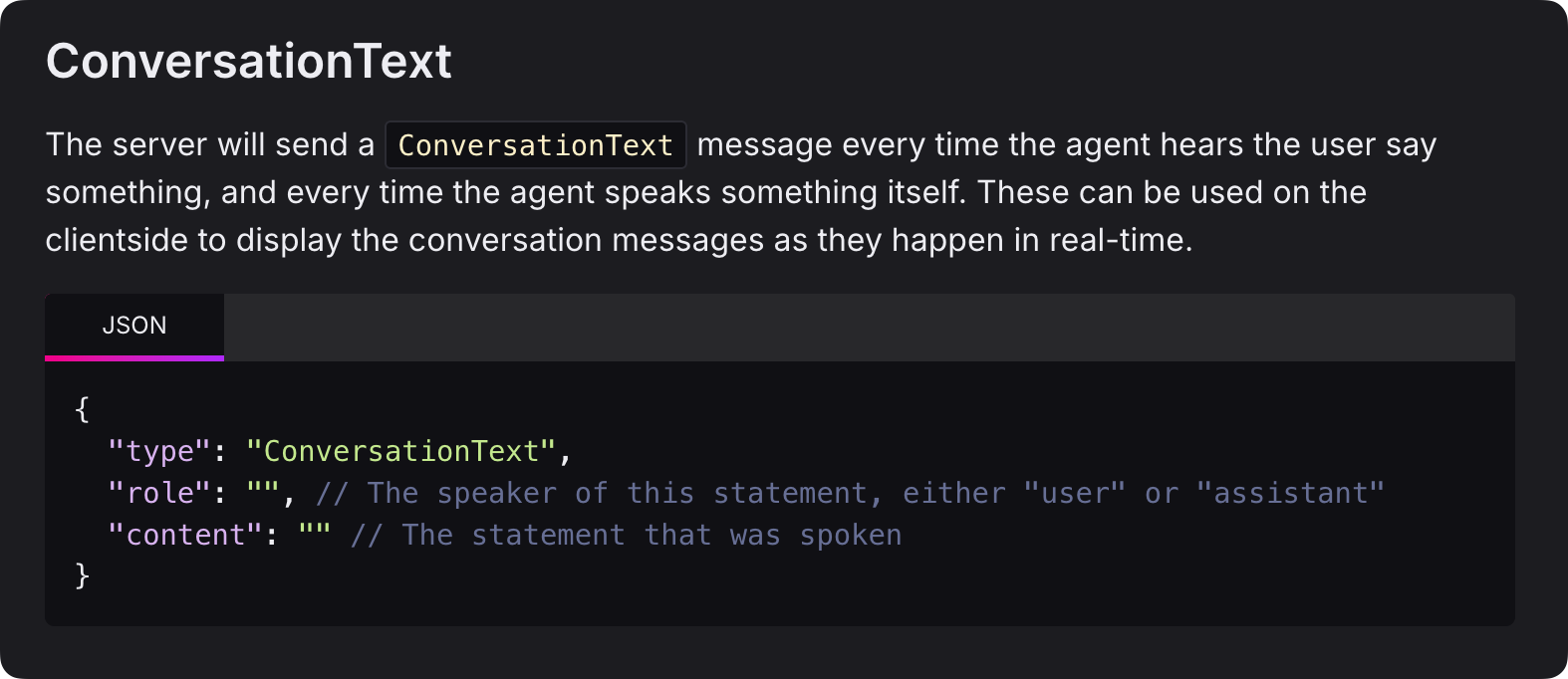
Newsletter Title: AI Must Think Before IT Speaks, But Sometimes it Shouldn't Speak At All
AI Must Think Before IT Speaks, But Sometimes it Shouldn't Speak At AllHave you ever wished your LLM would share it's thoughts in real-time so you could also guide it in real-time?I’ve repeatedly observed that while getting good at thinking before they speak, large language models should also be able to think without saying anything. This is a key nuance in agent design. There’s a preponderance of evidence to suggest today’s crop of agentic frameworks¹, such as Deepgram’s Voice-to-Voice API and OpenAI’s Real-time Voice API, must support the ability to respond in a manner that may or may not require saying something. Perhaps agentic solution designers want a conversational turn to produce thoughts that aren’t said openly to users. In some cases, AI applications only need the underlying thoughts or thought processes the LLM traversed. “It goes without saying” is the adage that comes to mind. This is adjacent to the overarching challenge that we all face—LLMs often speak before they think.
Prompting techniques in the latest frontier models make it easier to encourage better output from LLMs who are more capable of thinking before speaking. These techniques can force the LLMs to slow down, chill, and ponder all the facts before reaching early conclusions. With that challenge mostly behind us, a new challenge has emerged.
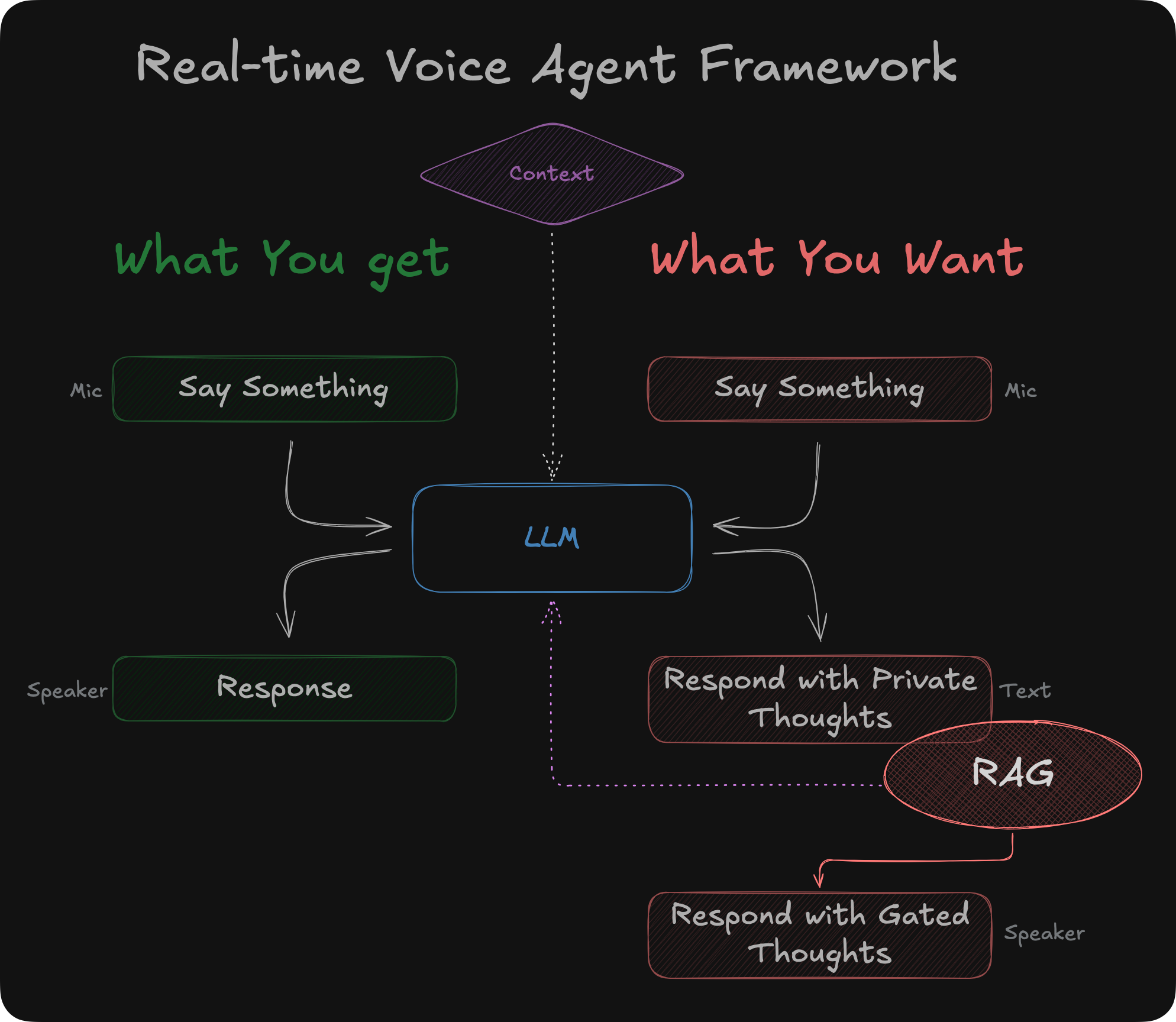
A unique form of retrieval-augmented generation may often gate an agent’s next utterance. I’m building real-time voice systems today that require filtered responses. However, real-time agentic voice frameworks vastly assume that with each conversation turn, there’s a response, and that response is transformed into audible words through an audio buffer stream unimpeded to the user’s ears. Herein lay the rub - how do you intercept something the agent is about to blurt out? Audio is binary data. You cannot easily filter it like a chatbot that generates text. The binary data is being streamed directly to a device speaker. When the agent has determined what to say, it’s out of the barn. You can’t unsay stuff. So, if this gating aspect is an integral part of a voice AI solution—and I would argue that this is almost always the case—you must deny your real-time voice agents direct access to speakers, intercept their responses, and generate a better, recalibrated response. It is worth noting that Deepgram supports this requirement to a degree. The Real-time Voice API allows all TTS² audio output to flow unimpeded to the speaker. Simultaneously, it generates a real-time Armed with this dual real-time pathway, you can suppress the “say-what-you-think” approach and lean into a process that evaluates what it wants to say. You can also take alternative steps, such as revealing more data to the LLM or suggesting a better response. This lands squarely in the RAG (retrieval-augmented generation) realm, but it’s a novel use of RAG. Another revealing element of the Deepgram architecture is the This is precisely my point - non-verbalized agent thought! However, this event doesn’t seem to fire all the time, nor can it be persuaded to inform reliably. Perhaps there’s a switch on their roadmap to enforce this behavior. Just Think, Don’t SpeakBut even with Deepgram’s advanced architecture, they don’t make it easy. You must still generate new audio (in the case of a voice agent) and play it. I won’t get into the complexities of doing this in real-time.
Unlike traditional RAG processes, the RAG circle in the diagram must accommodate several non-trivial steps.
Thoughts? 1 A comprehensive API designed to unify the development of agents. Gemini, GPT-4, and many other frameworks exist to simplify the delicate balance between text completions and memory that produces a helpful agent. 2 Text-to-Speech. You're currently a free subscriber to Impertinent. For the full experience, upgrade your subscription.
|